최근 각광받는 MSA 구조, 분산 시스템 구조에서 서버간 네트워크 통신은 매우 중요하다. 특히 네트워크를 통한 API 호출은 언제 어떻게 실패할지 예측하기 어렵기 때문에 이를 감시할 수 있는 모니터링 기술도 매우 중요하게 평가받고 있다. Datadog 같은 기업의 클라우드 환경 솔루션도 이런 분산 시스템 모니터링과 실시간 오류, 성능 분석을 위한 사용자의 니즈를 기반으로 급속하게 성장하고 있는 중이다.
Retry는 똑똑해야 한다.
이런 분산 시스템에서 서버와 서버간 API 호출 실패에 대한 재시도는 매우 중요한 행위이다. 1번의 네트워크 호출 실패로 서비스의 비지니스 로직을 모두 실패처리하거나 fallback 처리하는 것은 몇 번 다시 호출하는 것보다 큰 리소스 낭비가 될 수 있기 때문이다. 따라서 보통은 특정 API 호출 실패 상황에서는 최대 3번의 호출 재시도를 하는 등의 방법을 많이 사용한다. 대표적인 예로 명확한 비지니스 로직의 실패의 응답을 받는 상황이 아닌 네트워크의 일시적 장애로 Read Timeout 실패 응답을 받는 경우가 재시도를 해볼만한 상황이다.
하지만 문제는 이런 평범한 재시도 행위 자체가 대부분은 의미없거나 네트워크에 부담을 더 가중하는 결과로 끝난다는 점에 있다. 대부분의 Read Timeout 상황은 특정 시간동안 네트워크 이슈가 지속되는 경우가 많기 때문에 3회 재시도를 하더라도 모두 실패로 끝날 가능성이 높다. 또한 재시도 자체를 시간 간격을 두고 하지 않는 경우 가뜩이나 문제가 발생한 네트워크에 더 부담을 줄 가능성이 크다. 예를들어 트래픽이 몰려서 요청 자체가 지연되고 있는데 모든 클라이언트가 재시도를 연속으로 시도한다고 생각해보자. 네트워크 트래픽이 최대 3배 더 증가할 것이다. 따라서 Retry 행위는 똑똑해야 한다.
Exponential Backoff
간단하게 일정 시간 간격을 두고 Retry를 한다고 생각해보자. 이 경우도 일정 시간의 여유를 줬지 사실 동일하게 네트워크 부하를 줄 가능성이 크다. 그래서 일반적인 방법은 점진적으로 시간 간격이 늘어나는 Exponential Backoff 전략을 사용하는 것이다. 이 경우 지수에 비례하여 Backoff 시간을 조절한다. 예를 들어 첫번째 재시도를 위한 대기 시간은 100ms, 두번째 재시도를 위한 대기시간은 200ms, 세번째 재시도를 위한 대기시간은 400ms 처럼 2의 지수배만큼 늘어나는 방식이다.
이런 방식은 재시도 횟수가 증가할수록 Backoff 시간이 증가하므로 네트워크에 갑작스럽게 트래픽을 부담시키는 것을 피할 수 있다. 하지만 눈치빠른 사람들은 이 방법도 한계가 있다는 것을 금방 알 수 있다. 어차피 동시에 요청이 몰린다면 똑같은 시간 간격으로 모든 재시도가 동일하게 몰릴 것이기 때문이다. 따라서 조금 더 똑똑한, 교묘한 방법이 필요하다.
Jitter
이런 상황에서 등장하는 개념이 Jitter(지연변이)이다. 원래 Jitter는 데이터 통신 용어로 사용될 때는 패킷 지연이 일정하기 않고, 수시로 변하면서 그 간격이 일정하지 않는 현상을 의미한다. Jitter 개념을 Retry에 이용하면 API를 요청하는 클라이언트 간의 동일한 재시도 시간 간격에 무작위성을 추가하여 서로 요청하는 시간대의 동시성(?)을 분산시킬 수 있다.
간단하게 이 개념을 적용한다면 지수로 증가하는 Backoff 시간에 일정 범위 안의 랜덤 대기 시간을 추가적으로 더하는 것이다. 이런 방식이라면 동시에 수많은 클라이언트가 요청과 재시도를 하는 경우 각각의 요청은 재시도 횟수가 증가할수록 랜덤하게 추가된 시간으로 인해서 분산된다.
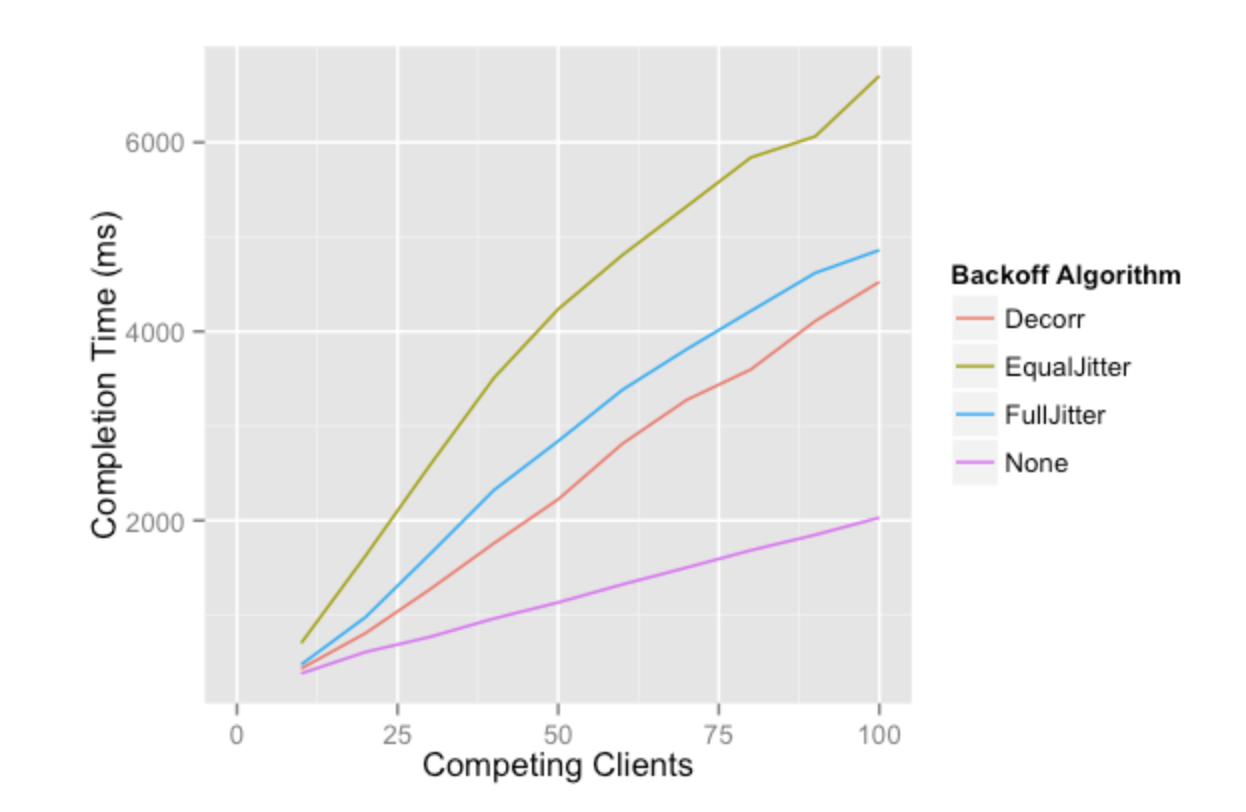
AWS의 Exponential Backoff
현존하는 가장 큰 클라우드 서비스인 AWS 에서도 모든 오류 Retry 행위에 Exponential Backoff 알고리즘을 Jitter와 함께 사용한다. 아래 AWS 문서를 참고하면 눈으로 파악하기 쉬운 그래프가 함께 있어서 더욱 이해하기 좋다. 이 문서의 특징은 Jitter 전략도 여러가지 방식으로 적용이 가능하다는 것이고, 이를 더 똑똑하게 적용하는 방법이 있다는 것이다.
Exponential Backoff And Jitter | Amazon Web Services
Introducing OCC Optimistic concurrency control (OCC) is a time-honored way for multiple writers to safely modify a single object without losing writes. OCC has three nice properties: it will always make progress as long as the underlying store is available
aws.amazon.com
Reactor의 Retry 전략
Spring Boot의 WebFlux에서도 WebClient가 호출을 재시도하는 경우를 위해서 Retry 전략을 지원해준다. 아래 링크에 글쓴이 분의 자세한 설명이 포함되어 있으니 참고하면 도움이 될 것 같다.
Spring WebFlux에서 Error 처리와 Retry 전략
Spring WebFlux에서 Mono 또는 Flux를 처리하다 보면 Exception 등 Error가 발생하는 경우가 많습니다. 이 때 Exception을 throw하지 않고 Reactive Stream을 Graceful 하게 처리할 수 있는…
medium.com
'개발 이야기 > ETC' 카테고리의 다른 글
| 성능 테스트, 부하 테스트, 스트레스 테스트란? (0) | 2021.08.19 |
|---|---|
| Gradle Wrapper란? (0) | 2021.03.23 |
| 임의(Arbitrary)값과 무작위(Random)값은 어떻게 다를까? (0) | 2021.03.18 |
| [기타] 병행(Concurrency)과 병렬(Parallelism)의 차이에 대해서 (2) | 2021.02.24 |
| [기타] 개발 환경(Phase)이란 무엇일까? (0) | 2021.02.22 |



